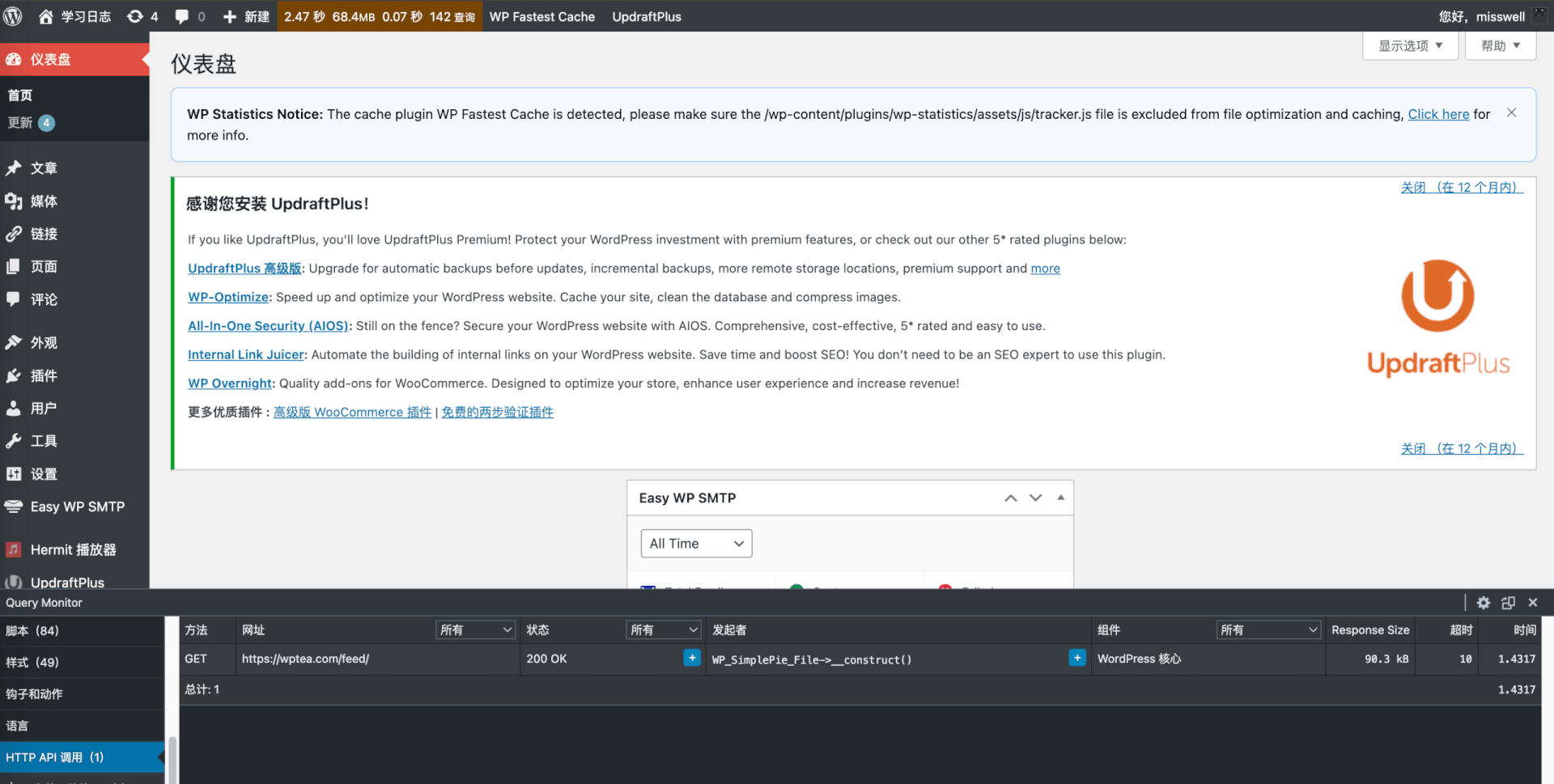
有发往 https://wptea.com/feed/ 的请求,耗时一秒多,禁用掉 WP-China-Yes

另外阻止向WordPress的更新请求,安装插件 Disable All WordPress Updates,必要时再开启更新
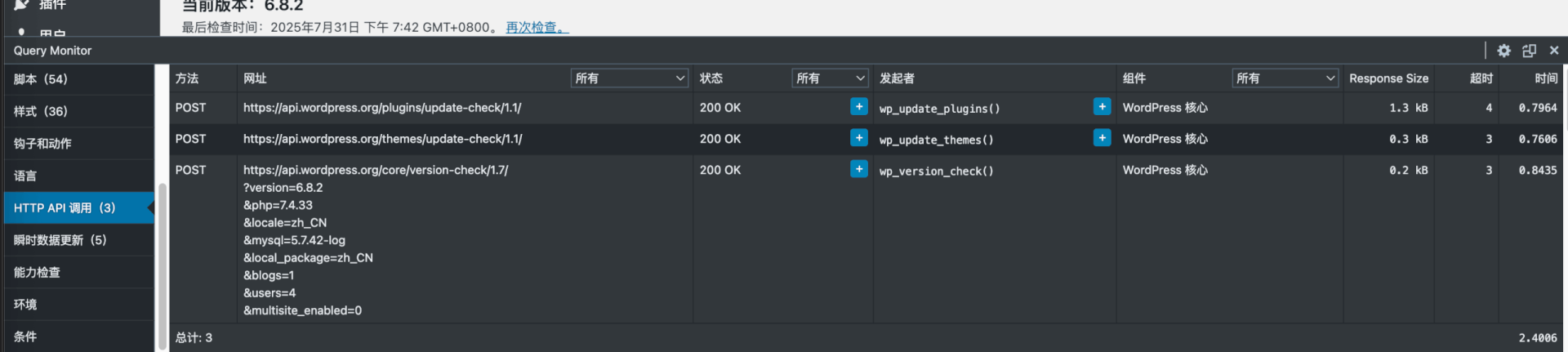
有发往 https://wptea.com/feed/ 的请求,耗时一秒多,禁用掉 WP-China-Yes
另外阻止向WordPress的更新请求,安装插件 Disable All WordPress Updates,必要时再开启更新
mybatis 创建临时表
<insert id="dropTempTable">
DROP TEMPORARY TABLE IF EXISTS temp_table${uuid};
</insert>
<insert id="createTempTable">
CREATE TEMPORARY TABLE IF NOT EXISTS temp_table${uuid} (
id VARCHAR(50) PRIMARY KEY
);
</insert>
<!-- 插入数据到临时表 -->
<insert id="insertTempTableData">
INSERT INTO temp_table${uuid} (id)
VALUES
<foreach collection="orgIdList" item="id" separator=",">
(#{id})
</foreach>
</insert>
mysql 第一张表为用户表,第二张表为用户与组织的关系表,用户与组织一对多的关系,已知多个用户组织id,查询哪些用户属于这些组织
你希望从组织 ID 为 1、2、3 的用户中查询,同时列出他们所有的组织 ID,包括那些不在 1、2、3 之中的,如 4 和 5。这样,我们需要一个两步的查询:
1、2、3 的用户。我们可以使用子查询来实现这一点:
SELECT u.user_id, u.user_name, GROUP_CONCAT(uo.organization_id ORDER BY uo.organization_id) AS organization_ids
FROM users u
JOIN user_organization uo ON u.user_id = uo.user_id
WHERE u.user_id IN (
SELECT uo.user_id
FROM user_organization uo
WHERE uo.organization_id IN (1, 2, 3)
)
GROUP BY u.user_id, u.user_name;SELECT uo.user_id FROM user_organization uo WHERE uo.organization_id IN (1, 2, 3) 用于找到所有组织 ID 为 1, 2, 3 的用户 ID。JOIN 连接 users 表和 user_organization 表,以获取用户及其所有组织 ID。WHERE u.user_id IN (...) 仅选择在子查询中找到的用户 ID。GROUP_CONCAT(uo.organization_id ORDER BY uo.organization_id) 聚合用户的所有组织 ID,并按升序排列。假设 Alice 拥有组织 ID 1, 2, 4, 5,Bob 拥有组织 ID 2, 3,Charlie 拥有组织 ID 1, 2, 3, 4,而你查询的组织 ID 是 1, 2, 3,那么查询结果会是:
| user_id | user_name | organization_ids |
|---|---|---|
| 1 | Alice | 1,2,4,5 |
| 2 | Bob | 2,3 |
| 3 | Charlie | 1,2,3,4 |
在这个结果中,organization_ids 列包括用户所拥有的所有组织 ID,而不仅仅是查询条件中的那些组织 ID。
docker run -itd --name docker-mysql8.0 -p 3306:3306 -e MYSQL_ROOT_PASSWORD=qwer1234 mysql --lower_case_table_names=1docker run -itd --name docker-mysql5.7 -p 3307:3306 -e MYSQL_ROOT_PASSWORD=qwer1234 bingozhou/mysql5.7 --lower_case_table_names=1MySQL 优化分页查询
以 t_sys_log 表为例,3774851条数据,占用空间1.01G,24个字段
SELECT * FROM `t_sys_log` order by create_time desc limit 100000,10耗时 88.345秒
SELECT id FROM `t_sys_log` order by create_time desc limit 100000,10耗时 0.336秒
所以联表查询
SELECT * FROM `t_sys_log` t1 JOIN
(SELECT id FROM `t_sys_log` order by create_time desc limit 100000,10) t2
ON t1.id = t2.id耗时 0.453秒
偏移量更大一点
SELECT * FROM `t_sys_log` order by create_time desc limit 1000000,10耗时 12.687秒
SELECT * FROM `t_sys_log` t1 JOIN
(SELECT id FROM `t_sys_log` order by create_time desc limit 1000000,10) t2
ON t1.id = t2.id耗时 0.617秒
MySQL的排序时间 create_time 字段需不需要添加索引
以 t_sys_log 表为例,3774851条数据,占用空间1.01G,24个字段
SELECT * FROM `t_sys_log` order by create_time desc limit 10000,10 create_time
不加索引 耗时 8.051 秒
加索引 耗时 0.468 秒
结论,需要加索引
要在CentOS操作系统中开启端口,可以按照以下步骤操作:
使用命令firewall-cmd --zone=public --add-port=端口号/协议来开启指定端口。例如,要开启端口80的TCP协议,可以使用如下命令:
sudo firewall-cmd --zone=public --add-port=80/tcp
然后需要重新加载防火墙规则,以使更改生效。可以使用命令firewall-cmd --reload来重新加载规则:
sudo firewall-cmd --reload
可以使用命令firewall-cmd --list-ports来查看当前开启的端口列表:
sudo firewall-cmd --list-ports
通过以上步骤,您可以在CentOS系统中成功开启指定的端口。
export const sleep = (ms) => new Promise((resolve) => setTimeout(resolve, ms));
export const awaitTime = async (cb, ms) => {
const start = new Date().getTime();
const res = await cb();
const end = new Date().getTime();
if (end - start < ms) {
await new Promise((resolve) => {
setTimeout(resolve, ms - (end - start));
});
}
return res;
};
mysql 中 使用order by进行排序,但排序的字段是 字符串加数字的形式,如何排序?
如果字符串和数字的长度都是不确定的,可以通过更复杂的 SQL 语句来处理。这通常涉及将字符串和数字部分分开,然后进行排序。下面是一个处理这种情况的示例。
假设有一个表 your_table,字段名为 mixed_column:
CREATE TABLE your_table (
mixed_column VARCHAR(255)
);
INSERT INTO your_table (mixed_column) VALUES
('A1'), ('A2'), ('A10'), ('B1'), ('B2'), ('B10'), ('AA1'), ('AA2'), ('AA10');可以使用以下查询来对字段进行排序:
SELECT *
FROM your_table
ORDER BY
-- 提取字符串部分
SUBSTRING_INDEX(mixed_column, (SELECT SUBSTRING_INDEX(mixed_column, '', -1) FROM your_table WHERE mixed_column REGEXP '[0-9]' LIMIT 1), 1),
-- 提取数字部分并填充到10位
LPAD(
IFNULL(
SUBSTRING(mixed_column FROM LENGTH(SUBSTRING_INDEX(mixed_column, (SELECT SUBSTRING_INDEX(mixed_column, '', -1) FROM your_table WHERE mixed_column REGEXP '[0-9]' LIMIT 1), 1)) + 1),
'0'
),
10, '0'
);解释:
提取字符串部分:SUBSTRING_INDEX(mixed_column, (SELECT SUBSTRING_INDEX(mixed_column, '', -1) FROM your_table WHERE mixed_column REGEXP '[0-9]' LIMIT 1), 1) 通过正则表达式找出包含数字的子字符串的位置,并用 SUBSTRING_INDEX 提取字符串部分。
提取数字部分并填充到10位:LPAD(...) 用前导零填充数字部分以确保数字按数值排序。IFNULL(SUBSTRING(...), '0') 用于处理没有数字部分的情况。
这个查询考虑了字符串和数字部分长度不确定的情况,并确保按照数值顺序排序。你可以根据实际情况进一步调整查询。如果数据库的字段和内容有更多的变化,还需要进一步调整正则表达式和字符串处理函数的参数。
如果你只是想快速地在文件末尾添加一些数据来改变hash值,并且不介意文件变得不可播放(或者你知道如何移除添加的数据以恢复文件的可播放性),你可以使用简单的shell命令。但请注意,这样做通常会使视频播放器无法识别或播放文件。
下面是一个简单的shell脚本示例,它会在当前目录下的所有视频文件末尾追加一个字符串,从而改变它们的hash值:
#!/bin/bash
APPEND_DATA="This is some extra data to change the hash."
# 遍历当前目录下的所有视频文件
for file in *.{mp4,mov,avi,mkv}; do
if [ -f "$file" ]; then
# 检查文件是否真的是视频文件(可选)
# file "$file" | grep -q 'video'
# if [ $? -eq 0 ]; then
# 在视频文件末尾追加数据
echo "$APPEND_DATA" >> "$file"
echo "Appended data to $file"
# fi
fi
done重要提示:这个脚本会破坏视频文件,使它们无法被正常播放。如果你只是想测试hash值的变化,并且不关心文件的可播放性,那么可以运行这个脚本。但是,如果你想要保留视频的可播放性,你应该寻找其他方法,比如使用mp4box添加元数据或轨道。
如果你决定使用上面的脚本,请确保在运行之前备份你的视频文件。要运行脚本,请保存到一个文件中(比如change_video_hashes.sh),然后在终端中使其可执行并运行它:
chmod +x change_video_hashes.sh
./change_video_hashes.sh请记住,这种方法不是处理视频文件的推荐方式,因为它会导致视频文件损坏。如果你需要更改视频文件的hash值同时保持其可播放性,你应该考虑使用更专业的工具或方法。